The ProteomeXchange (PX) Consortium of proteomics assets (http://www.proteomexchange.org) was formally began in 2011 to standardize data submission and dissemination of mass spectrometry proteomics data worldwide. We give an summary of the present consortium actions and describe the advances of the previous few years.
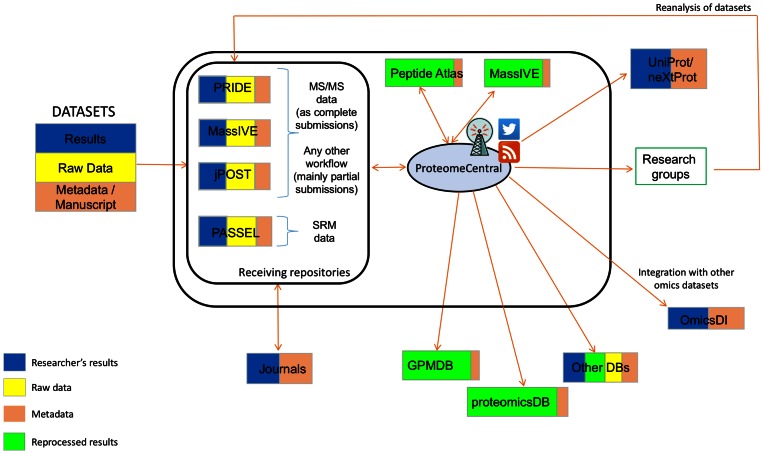
Augmenting the PX founding members (PRIDE and PeptideAtlas, together with the PASSEL useful resource), two new members have joined the consortium: MassIVE and jPOST. ProteomeCentral stays as the widespread data entry portal, offering the means to seek for data units in all taking part PX assets, now with enhanced data visualization parts.
We describe the up to date submission tips, now expanded to incorporate 4 members as a substitute of two. As demonstrated by data submission statistics, PX is supporting a change in tradition of the proteomics subject: public data sharing is now an accepted normal, supported by necessities for journal submissions ensuing in public data launch turning into the norm. More than 4500 data units have been submitted to the numerous PX assets since 2012.
Human is the most represented species with roughly half of the data units, adopted by a few of the primary mannequin organisms and a rising listing of greater than 900 various species. Data reprocessing actions have gotten extra distinguished, with each MassIVE and PeptideAtlas releasing the outcomes of reprocessed data units. Finally, we define the upcoming advances for ProteomeXchange.
The ProteomeXchange (PX) Consortium of proteomics assets was formally began in 2011 to standardize data submission and dissemination of mass spectrometry proteomics data worldwide. We give an summary of the present consortium actions and describe the advances of the previous few years. Augmenting the PX founding members (PRIDE and PeptideAtlas, together with the PASSEL useful resource), two new members have joined the consortium: MassIVE and jPOST. ProteomeCentral stays as the widespread data entry portal, offering the means to seek for data units in all taking part PX assets, now with enhanced data visualization parts.
We describe the up to date submission tips, now expanded to incorporate 4 members as a substitute of two. As demonstrated by data submission statistics, PX is supporting a change in tradition of the proteomics subject: public data sharing is now an accepted normal, supported by necessities for journal submissions ensuing in public data launch turning into the norm. More than 4500 data units have been submitted to the numerous PX assets since 2012. Human is the most represented species with roughly half of the data units, adopted by a few of the primary mannequin organisms and a rising listing of greater than 900 various species. Data reprocessing actions have gotten extra distinguished, with each MassIVE and PeptideAtlas releasing the outcomes of reprocessed data units. Finally, we define the upcoming advances for ProteomeXchange.
INTRODUCTION
Life sciences as an entire has a powerful custom of open data dissemination. Prime examples of long-running and profitable consortia to systematically gather, alternate and disseminate biomolecular data are the International Nucleotide Sequence Database Collaboration ( for DNA sequence data, and the worldwide Protein Data Bank () for protein construction data. However, in another life science domains, open data sharing has been for a very long time extra the exception than the norm. Yet in latest years, main initiatives in these different domains have efficiently expanded the apply of public data sharing.
One such instance is the ProteomeXchange (PX) Consortium
The implementation of the PX Consortium formally began in 2011 with the general goal to offer a typical framework and infrastructure for the cooperation of proteomics assets by defining and implementing constant, harmonized, user-friendly data deposition and alternate procedures amongst the members. In the first steady implementation of the data workflow PRIDE (now referred to as PRIDE Archive) was the level of submission for tandem MS experiments (the hottest experimental strategy in the proteomics subject), whereas PeptideAtlas offered a repository for SRM (Selected Reaction Monitoring) experiments referred to as PASSEL (PeptideAtlas SRM Experiment Library) . A standard data entry portal referred to as ProteomeCentral was additionally developed (, offering the means to seek for data units in all taking part PX assets. This performance was made potential since the PX companions agreed to offer a baseline set of experimental and technical metadata for all data units, which is encoded in the PX XML format ().
Based on quickly growing availability of open data, reuse of public proteomics data is flourishing in the subject (see (), as exemplified in one among the drafts of the human proteome revealed in Nature . To facilitate data reuse and reanalysis, the PX companions totally assist the open data codecs developed below the umbrella of the Proteomics Standards Initiative (PSI) ( and actively develop and preserve open-source software program to assist the requirements (.
Here, we are going to present an replace of the ProteomeXchange consortium since the unique paper was revealed in 2014 (), together with an outline of the up to date submission tips, which now mirror P’s growth to 4 consortium members. We can even describe the enhancements in the widespread interface at ProteomeCentral, spotlight totally different statistics to show the huge adoption of PX in the subject and focus on future developments.
EXPANSION OF THE CONSORTIUM AND UPDATED SUBMISSION GUIDELINES FOR ORIGINAL DATA SETS
Since the unique implementation of the PX data workflow, two new assets have joined PX: the MassIVE repository (University of California San Diego, CA, USA, joined in June 2014, and the lately developed jPOST useful resource (a number of establishments, Japan,) has simply joined PX in July 2016, thus demonstrating PX’s unifying function in the proteomics group by inclusion of members that weren’t a part of the preliminary consortium. The jPOST system was developed primarily based on the semantic net know-how utilizing the useful resource description framework data mannequin.
The PX receiving repositories talked about above (PRIDE, PASSEL, MassIVE and jPOST) retailer MS proteomics data as initially produced and analyzed by the scientists and supply personal entry for reviewers and journal editors throughout the manuscript overview course of. All the submitted data units are assigned a novel and common identifier of the format PXDnnnnnn , though repository-specific identifiers can be offered. The up to date submission tips can be found at
On the different hand, ‘Partial’ submissions include end result information
There are two primary data submission workflows, referred to as ‘Complete’ and ‘Partial’. For each varieties, a set of widespread experimental metadata (encoded in the PX XML format), uncooked data mass spectra and the submitter’s outcomes are all the time obligatory. The distinction lies in the means the processed peptide and protein identification outcomes are dealt with. In the case of a ‘Complete’ data set, it’s potential for the receiving PX repository to parse, ingest and straight join the identification outcomes with the submitted mass spectra. This may be achieved if the processed outcomes and the corresponding spectra can be found in supported open data codecs. In some instances, it is usually potential to make use of repository interfaces to help with the conversion of information from proprietary codecs to the supported open codecs (e.g. MassIVE helps on-line conversion of Thermo RAW information to plain mzML () information).
On the different hand, ‘Partial’ submissions include end result information that aren’t in codecs that may be parsed, and thus ingested, by the receiving repository. The metadata nonetheless make the data units findable in the receiving repository and in ProteomeCentral. These data units could then be freely downloaded and interpreted if the downloader has appropriate software program to parse the information.
Or the data could also be reprocessed from the obligatory uncooked data. This mechanism is required for the output of instruments not supporting open requirements (see above), which is especially the case for data workflows totally different from data dependent acquisition (DDA) approaches. Instead, the corresponding outcomes information output by the non-compliant software program instruments (in heterogeneous codecs) are made obtainable for obtain. Thus, utilizing the ‘Partial’ submission mechanism, nearly any kind of proteomics data workflows may be supported. In reality, PX assets retailer a big variety of data units coming from different data workflows resembling Data Independent Acquisition (DIA) approaches, top-down proteomics or MS imaging (), with MassIVE already supporting ‘full’ submissions for some DIA workflows, resembling MSPLIT-DIA’s) evaluation of SWATH-MS information.
Preparation of protein samples for NMR construction, operate, and small-molecule screening research
The general group of the Consortium is proven in Figure . Within PX, PRIDE, MassIVE and jPOST are thought of to be Universal Archival assets, and at current they’re centered on supporting tandem MS DDA workflows as ‘full’ submissions. (Thermo Fisher Scientific, Waltham, MA, USA), at the second of writing. PRIDE nonetheless helps PRIDE XML as a submission format for ‘full’ submissions as effectively, though submissions in this format are solely inspired if there is no such thing as a possible various for producing mzIdentML information. Once assist for mzIdentML is generalized, PRIDE will discontinue assist for PRIDE XML because of the limitations of the format. Another PSI data normal, referred to as mzTab (, shops identification and quantification data in a tabular format, and is supported by MassIVE and jPOST for performing ‘full’ submissions. In MassIVE, on-line conversion instruments can be found to assist conversion from tab-separated-value (TSV) codecs into mzTab. PRIDE plans to formally assist mzTab in the first half of 2017.
REPRESENTATION OF REPROCESSED DATA SETS
In PRIDE, all ‘full’ data units additionally get a digital object identifier, to enhance the monitoring of data units and enhance recognition for submitters. PASSEL, the remaining PX Archival useful resource, is a centered useful resource. As talked about in the introduction, it helps the submission of data coming from SRM workflows, however not different data workflows. In this case, the different PX members don’t actively solicit one of these data, and suggest submission to PASSEL. It is vital to notice that, though really helpful, this coverage can’t be fully enforced since the submitter chooses which useful resource to make use of for deposition. See Taban summary of the workflows that every PX useful resource helps.